AlphaGRPO applies GRPO to AR-Diffusion Native Unified Multimodal Models without an additional cold-start stage. With Decompositional Verifiable Reward (DVReward), it supports multimodal generation tasks such as Reasoning T2I and Self-Reflective Refinement through stable, interpretable supervision from open-source MLLMs.
First to introduce GRPO training to AR-Diffusion Native Unified Models. By optimizing the model's latent generative and reflective behaviors, AlphaGRPO supports multimodal generation tasks such as Reasoning T2I and Self-Reflective Refinement.
A fine-grained reward mechanism that decomposes user prompts into atomic verifiable questions across semantic alignment and visual fidelity, providing stable supervision via MLLM confidence scoring.
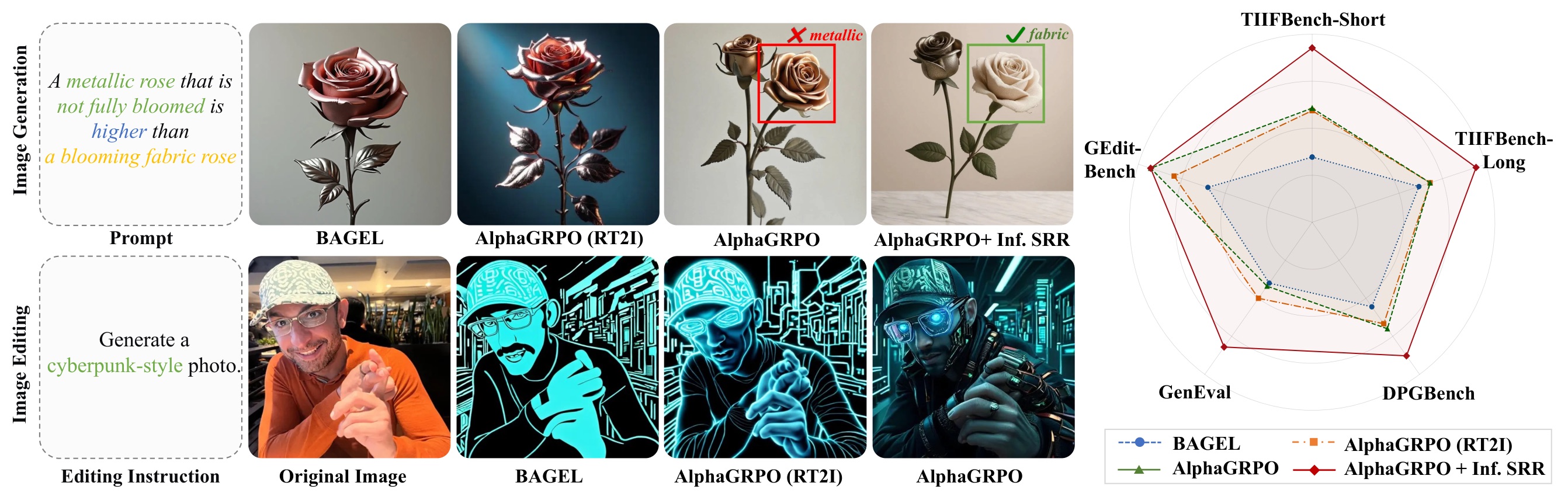
Consistent improvements on T2I benchmarks (GenEval, TIIF-Bench) and editing tasks (GEdit) — without training on editing tasks. Inference-time SRR further boosts performance up to +5.8%.
We propose AlphaGRPO, a novel framework that applies Group Relative Policy Optimization (GRPO) to AR-Diffusion Native Unified Multimodal Models (UMMs) to enhance multimodal generation capabilities. Our approach unlocks the model's intrinsic potential to perform advanced reasoning tasks: Reasoning Text-to-Image Generation, where the model actively infers implicit user intents, and Self-Reflective Refinement, where it autonomously diagnoses and corrects misalignments in generated outputs.
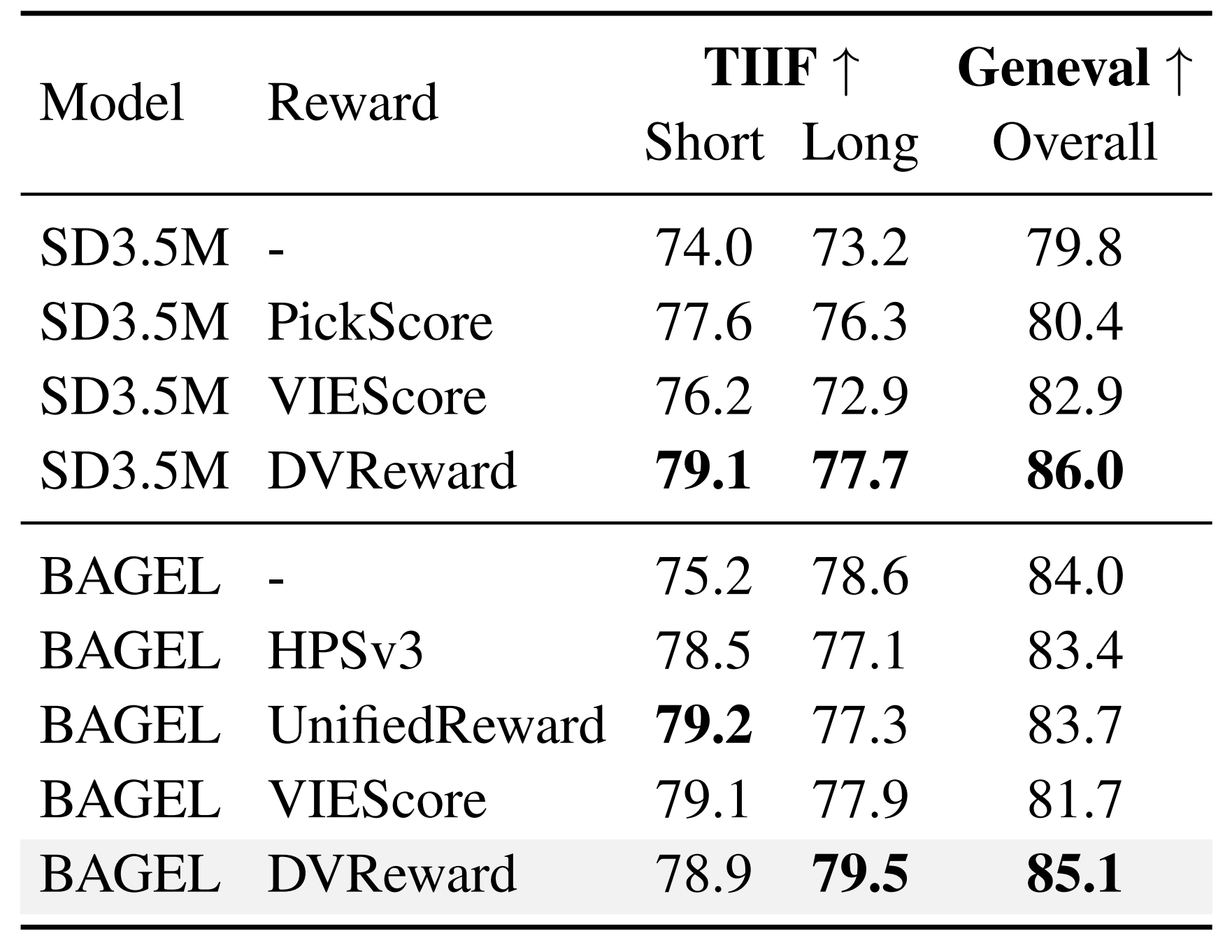
To address the challenge of providing stable supervision for real-world multimodal generation, we introduce the Decompositional Verifiable Reward (DVReward). Unlike holistic scalar rewards, DVReward utilizes an LLM to decompose complex user requests into atomic, verifiable semantic and quality questions, which are then evaluated by a general MLLM to provide reliable and interpretable feedback. Extensive experiments demonstrate that AlphaGRPO yields robust improvements across multimodal generation benchmarks, including GenEval, TIIF-Bench, DPG-Bench and WISE, while also achieving significant gains in editing tasks on GEdit without training on editing tasks.
When asked to verify if a generated image is correct, unified models exhibit confirmation bias — frequently asserting that outputs fulfill the original intent. However, switching to reflect mode (explicitly told to find mistakes) successfully breaks this loop, activating the model's understanding capability to identify errors.

Holistic scalar scoring (e.g., VIEScore) assigns identical scores to images with clear quality differences — acting as a "black box" that smooths over semantic discrepancies. In contrast, question-based probing via token logits produces highly discriminative signals (0.592 vs. 0.914).

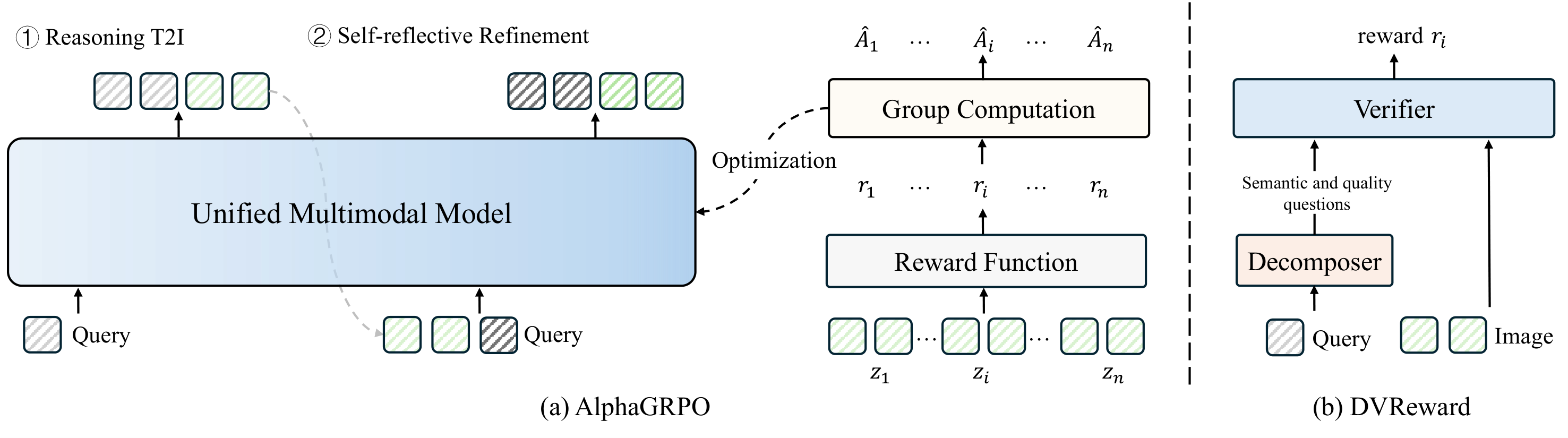
AlphaGRPO and DVReward. AlphaGRPO optimizes Reasoning T2I and Self-Reflective Refinement under unified multimodal trajectories, while DVReward decomposes user requests into atomic verifiable questions for reliable reward computation.
We conceptualize multimodal generation as a hybrid trajectory τ = (y, z1 → z0) that concatenates autoregressive reasoning tokens with a continuous visual diffusion path. Both Reasoning T2I and Self-Reflective Refinement share this unified formulation, enabling end-to-end GRPO optimization across text and image modalities.
DVReward transforms reward computation from black-box scoring into transparent verification: (1) An LLM decomposes user requests into atomic semantic and quality questions with physical visual grounding; (2) A pre-trained MLLM verifies each question using confidence scores derived from Yes/No token probabilities; (3) The final reward is the geometric mean of semantic and quality scores.
False-Positive Rectification: In self-reflective refinement, we enforce that trajectories failing to improve over the initial image receive the group minimum reward, preventing false-positive optimization signals.


Although AlphaGRPO is optimized at 512px, it improves 1024px generation results, indicating learned semantic alignment rather than pixel memorization.
Self-reflective refinement training also improves downstream T2I, matching or surpassing direct RT2I optimization on several metrics.
Test-time self-reflection further raises performance, including +4.5 on TIIF-Bench Short and +3.4 on GenEval over one-pass AlphaGRPO.
Without editing-task training, RT2I improves GEdit by +0.33 and SRR reaches +0.52 over BAGEL, showing transfer to instruction-based editing.
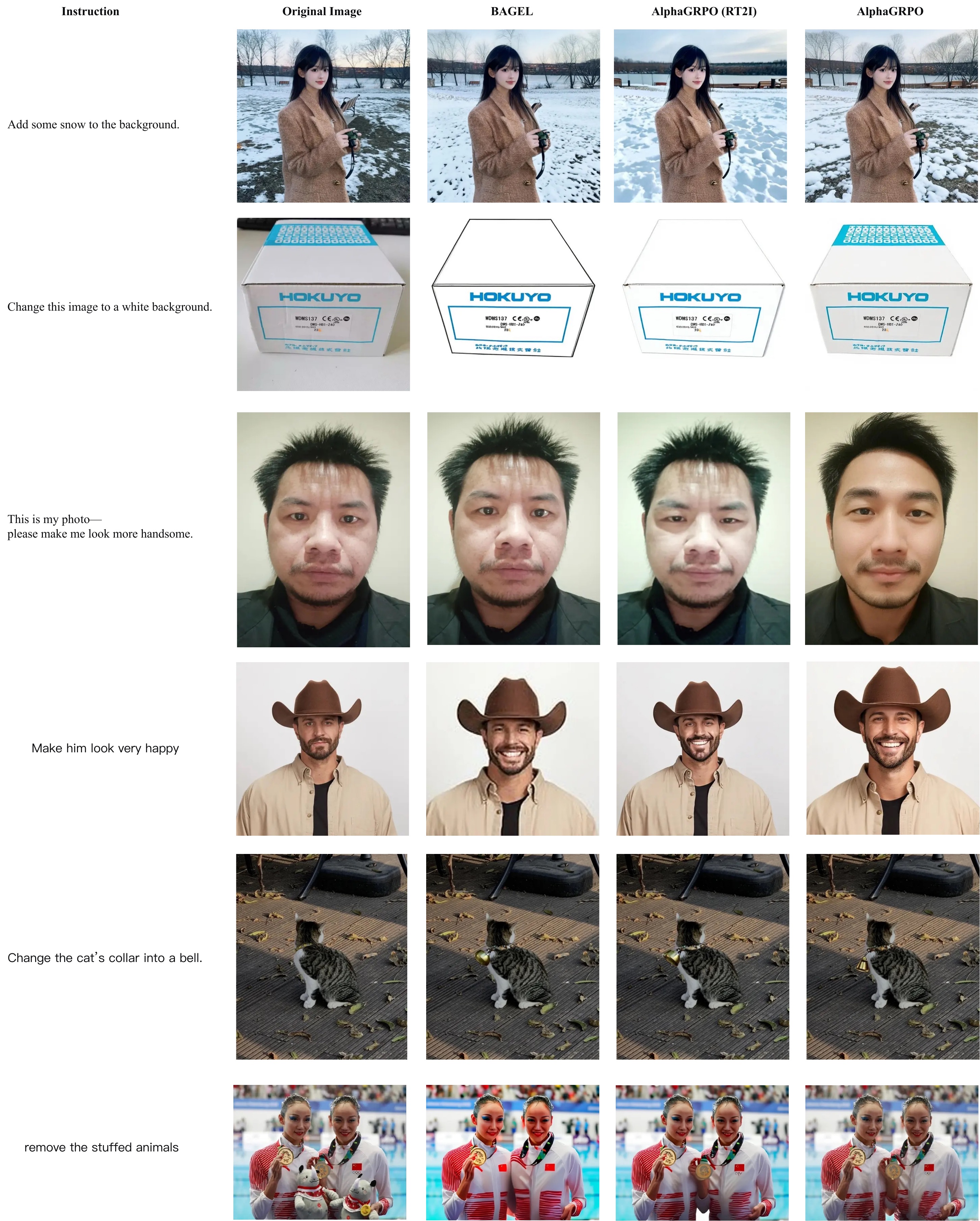
The first two panels are T2I visualizations. RT2I and SRR indicate the RL training task used to obtain each model variant, not a separate visualization setting. The final panel shows image editing examples.


@inproceedings{huang2026alphagrpo,
title={AlphaGRPO: Unlocking Self-Reflective Multimodal Generation in Unified Multimodal Models via Decompositional Verifiable Reward},
author={Huang, Runhui and Wu, Jie and Yang, Rui and Liu, Zhe and Zhao, Hengshuang},
booktitle={International Conference on Machine Learning (ICML)},
year={2026}
}